ブロードリスニングで読み解くジャングリア沖縄の良いところ・悪いところ

・2025年7月25日にオープンしたジャングリア沖縄。オープン前後でメディアが一斉に特集したことで、バーッと注目を集めることになった。このご時世に誕生したテーマパークに対して、人々がどのような印象を持ったのか気になった。
・すでにGoogleマップには700件近い口コミが寄せられている。残念ながら多くは低評価で、私が確認した7月30日時点では680件のレビューに対して星2つ程度の低評価になっていた。
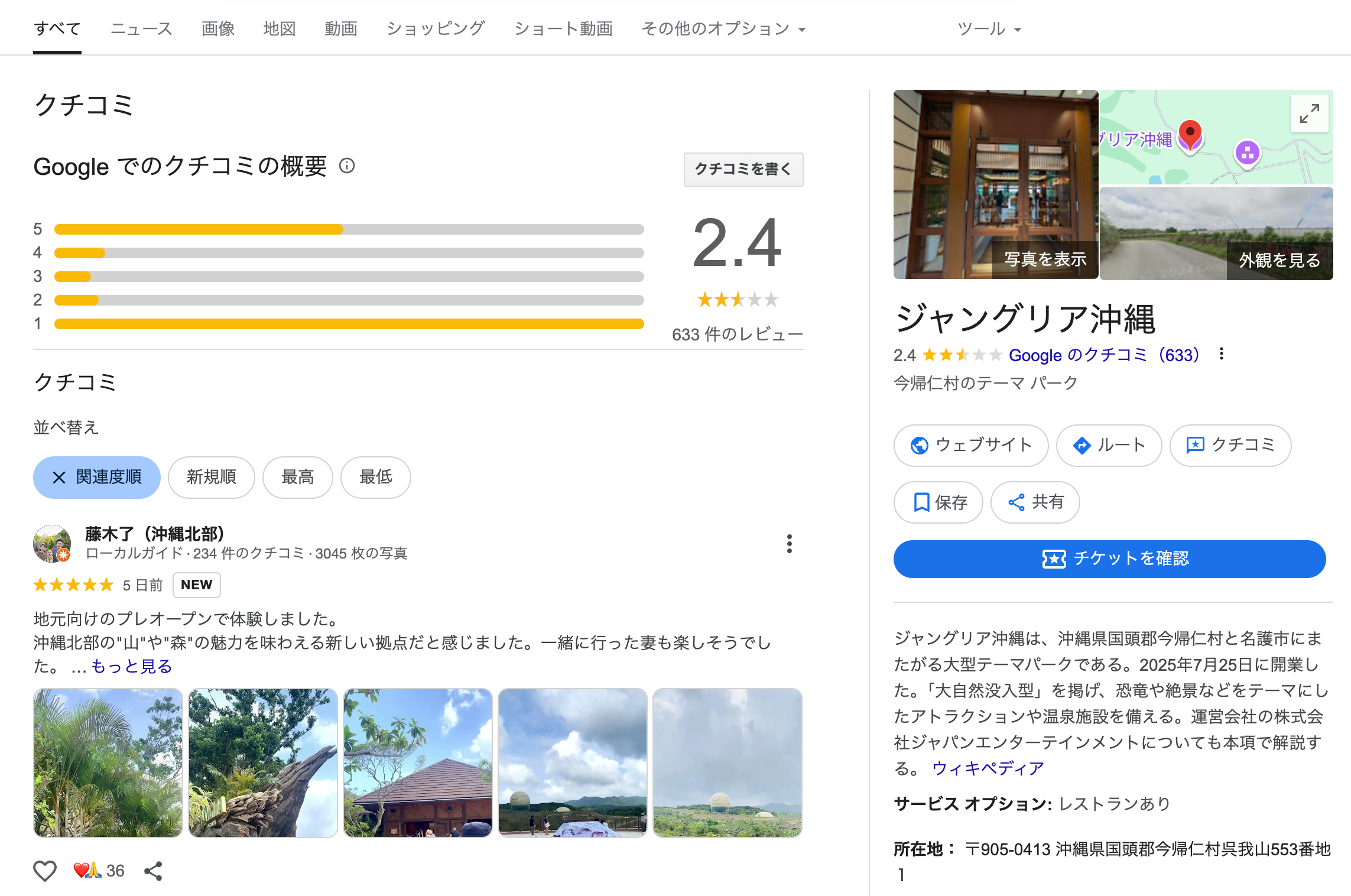
・さらに、関西万博と同様にアンチが湧いていて、それに輪をかけるようにメディアが煽り、あまり健全な状態ではないなー。私としては行ったことのない場所に対して評価することはできないし、ごく一部のユーザの感想だけ読んで納得することも避けたい。
・そこで、この680件のレビューをデータ分析することで、どのような点が課題なのかを自分なりに理解したいと思った。
レビューデータを集める
・まずはデータが必要です。Googleマップは、公式APIでは最新5件のレビューしか取得できず、厳しい。スクレイピングは禁止されているので、勝手に取得することは許可されない。そのため、今回はSerpApiを使用した。
・レビューを収集するには、ターゲットのプレイスIDが必要である。これはプレイス ID 検索ツールで簡単に調べることができる。
・Claudeで生成したコードは次のとおり。自身のSerpApiのキーをAPI_KEYに指定すれば実行できる。SerpApiの無料枠でデータ取得できたので助かった。
"""
ジャングリア沖縄のGoogleレビューデータを取得するスクリプト
SerpAPIを使用して全てのレビューを取得し、JSONファイルに保存する
"""
import json
import time
import os
from datetime import datetime
from serpapi import GoogleSearch
# 設定
API_KEY = ""
PLACE_ID = "ChIJk4Nn0Rj55DQRspSwLGXjC18" # ジャングリア沖縄
OUTPUT_DIR = "data"
OUTPUT_FILE = "junglia_reviews_raw.json"
DELAY_SECONDS = 1 # API呼び出し間隔(秒)
def setup_output_directory():
"""出力ディレクトリを作成"""
if not os.path.exists(OUTPUT_DIR):
os.makedirs(OUTPUT_DIR)
print(f"✅ 出力ディレクトリを作成しました: {OUTPUT_DIR}")
def get_reviews_page(next_page_token=None):
"""
レビューの1ページを取得
Args:
next_page_token (str): 次のページのトークン(初回はNone)
Returns:
dict: APIレスポンス
"""
params = {
"api_key": API_KEY,
"engine": "google_maps_reviews",
"hl": "ja",
"place_id": PLACE_ID,
"sort_by": "newestFirst"
}
# 2ページ目以降の場合
if next_page_token:
params["next_page_token"] = next_page_token
params["num"] = 20 # 2ページ目以降は最大20件まで指定可能
try:
search = GoogleSearch(params)
results = search.get_dict()
# APIエラーチェック
if "error" in results:
print(f"❌ APIエラー: {results['error']}")
return None
return results
except Exception as e:
print(f"❌ リクエストエラー: {str(e)}")
return None
def save_progress(all_reviews, page_count):
"""進捗を保存"""
progress_file = os.path.join(OUTPUT_DIR, f"progress_page_{page_count}.json")
with open(progress_file, 'w', encoding='utf-8') as f:
json.dump({
"timestamp": datetime.now().isoformat(),
"page_count": page_count,
"total_reviews": len(all_reviews),
"reviews": all_reviews
}, f, ensure_ascii=False, indent=2)
print(f"📝 進捗保存: ページ{page_count}, レビュー数{len(all_reviews)}件")
def scrape_all_reviews():
"""全レビューデータを取得"""
print("🚀 ジャングリア沖縄レビューデータ取得開始")
print(f"📍 Place ID: {PLACE_ID}")
all_reviews = []
all_metadata = []
next_page_token = None
page_count = 0
place_info = None
while True:
page_count += 1
print(f"\n📄 ページ {page_count} を取得中...")
# APIリクエスト
results = get_reviews_page(next_page_token)
if not results:
print("❌ データ取得に失敗しました")
break
# 1ページ目で場所情報を保存
if page_count == 1 and "place_info" in results:
place_info = results["place_info"]
print(f"🏢 施設名: {place_info['title']}")
print(f"⭐ 平均評価: {place_info['rating']}")
print(f"📊 総レビュー数: {place_info['reviews']}")
# レビューデータを追加
if "reviews" in results:
reviews = results["reviews"]
all_reviews.extend(reviews)
print(f"✅ {len(reviews)}件のレビューを取得")
print(f"📈 累計: {len(all_reviews)}件")
else:
print("⚠️ このページにレビューがありません")
# メタデータを保存
if "search_metadata" in results:
all_metadata.append({
"page": page_count,
"metadata": results["search_metadata"],
"pagination": results.get("serpapi_pagination", {})
})
# 10ページごとに進捗保存
if page_count % 10 == 0:
save_progress(all_reviews, page_count)
# 次のページトークンをチェック
if "serpapi_pagination" in results and "next_page_token" in results["serpapi_pagination"]:
next_page_token = results["serpapi_pagination"]["next_page_token"]
print(f"➡️ 次のページトークン取得済み")
else:
print("✅ 全ページの取得完了")
break
# API制限を考慮した待機
print(f"⏳ {DELAY_SECONDS}秒待機中...")
time.sleep(DELAY_SECONDS)
# 最終結果をまとめて保存
final_data = {
"collection_info": {
"timestamp": datetime.now().isoformat(),
"total_pages": page_count,
"total_reviews": len(all_reviews),
"api_key_used": API_KEY[:8] + "..." + API_KEY[-8:], # 部分的にマスク
"place_id": PLACE_ID
},
"place_info": place_info,
"reviews": all_reviews,
"metadata": all_metadata
}
# JSONファイルに保存
output_path = os.path.join(OUTPUT_DIR, OUTPUT_FILE)
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(final_data, f, ensure_ascii=False, indent=2)
print(f"\n🎉 データ取得完了!")
print(f"📁 保存先: {output_path}")
print(f"📊 総レビュー数: {len(all_reviews)}件")
print(f"📄 取得ページ数: {page_count}ページ")
return final_data
def main():
"""メイン処理"""
print("=" * 60)
print("🏝️ ジャングリア沖縄 レビューデータ収集ツール")
print("=" * 60)
# 出力ディレクトリ準備
setup_output_directory()
# データ収集実行
try:
data = scrape_all_reviews()
print("\n✅ 処理が正常に完了しました")
return data
except KeyboardInterrupt:
print("\n⚠️ ユーザーによって処理が中断されました")
return None
except Exception as e:
print(f"\n❌ 予期しないエラーが発生しました: {str(e)}")
return None
if __name__ == "__main__":
# 必要なライブラリのインストール確認
try:
from serpapi import GoogleSearch
except ImportError:
print("❌ serpapi ライブラリがインストールされていません")
print("💡 以下のコマンドでインストールしてください:")
print(" pip install google-search-results")
exit(1)
# 実行
main()
・取得したデータを眺めると、各ユーザの投稿にはユーザ名(name)や投稿内容(snippet)などの項目以外に、ユーザの累計レビュー数(reviews)が含まれる。これは便利で、いわゆるサクラレビューを除外できる。
・さらに、外国語で投稿されたレビューには日本語翻訳(translated)の項目が存在し、追加の翻訳は不要だった。
基礎データから見える傾向
・取得したデータから確認できる基礎的な傾向を以下にまとめる。
| 項目 | 数値 | 備考 |
|---|---|---|
| 総レビュー数 | 680件 | 2025年7月30日時点 |
| 平均評価 | 2.4点 | 5点満点中 |
| 初回投稿ユーザ | 168件 (29.7%) | 新規ユーザの割合 |
| 日本語レビュー | 488件 (66.0%) | |
| 日本語レビューの平均評価 | 2.79点 | |
| 外国語レビュー | 192件 (34.0%) | 中国語・韓国語が多数 |
| 外国語レビュー平均評価 | 1.41点 | |
| 外国語レビューの★1評価 | 162件 (84.4%) | 85%近くが最低評価 |
・いくつか興味深い点として、まず、初回投稿ユーザの割合は3割程度であること。普段レビューは行っておらず、今回の訪問をきっかけに投稿したか、新規アカウントを作って投稿したユーザ(サクラレビュー)だろうか。
・Googleマップレビューの仕様上「その人が本当に施設に訪問したか」を裏付けることはできない。実際に行っていなくても、レビューは投稿できてしまうので、信憑性の課題がある。
・また、外国語レビューは3割程度。そこそこ多い。ざっと目を通すと、中国語・韓国語によるレビューが目立つ。これらは平均評価が1.41点であり、全体の評価を下げている。日本人よりも外国人ユーザの評価が低いのは意外な事実だった。恐竜のアトラクションなどを見ていて、外国人ウケが良いものだと思っていたからだ。

ブロードリスニングでレビュー傾向を可視化する
・レビューをパラパラと見て行ったときに感じたのは「みんな結構ちゃんと書いてるな・・・」だった。ネガティブなコメントだからか、熱量がある。
・詳細な分析にあたって、ブロードリスニングという手法を使用した。これを効率的に行うTalk to the City(TttC)というツールがある。多様な意見をクラスタリングして、クラスター内の代表的な意見を見やすく表現してくれるプログラムである。
・せっかく良いツールではあるが、長い間更新されておらずそのままでは正常に動かなかったため、最新化・スマートフォンや日本語対応などカスタマイズを行い、自分なりに使いやすい状態に調整した。
- 元リポジトリ:https://github.com/AIObjectives/talk-to-the-city-reports
- 私のフォーク:https://github.com/sssshun664/talk-to-the-city-report-202507
・ここではTttCの詳細な紹介は行わないが、関心があれば以下などを参考にしてほしい。
・また、最終的に、累計レビュー投稿数が6件以上のユーザによるレビュー260件に絞り込んだ。
分析結果
・さて、260件のレビューの分析結果を見ていこう。

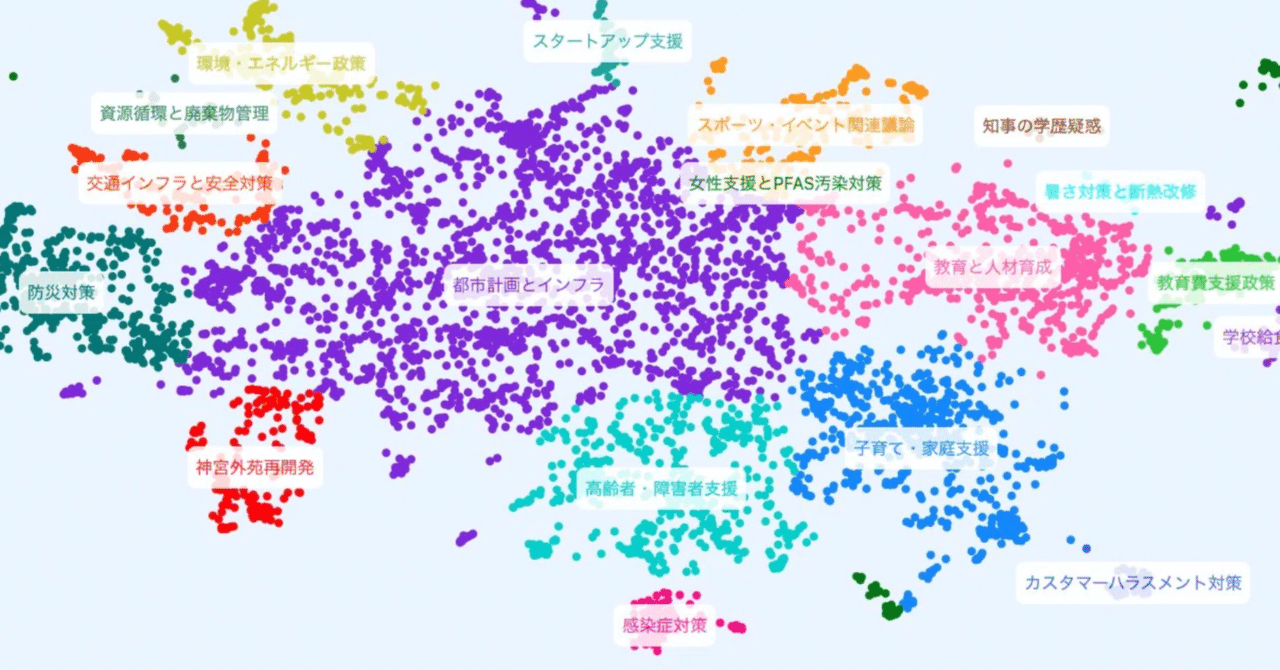
・TttCは各レビューから論点を抽出し、それらを意味的に類似したもの同士でクラスタリングする。今回260件のレビューから1,290件の論点(argument)が抽出され、それらが10のクラスターに分類された。
・一つケースを見てみよう。次のレビュー投稿がある。
7月25日のオープン初日は、行列が制御不能で混乱状態でした。チケットシステムは毎時クラッシュし、9時に到着してもまだ早すぎたため、一番人気のジープを諦めました。公園内の行列は日陰がなく、太陽と雨にさらされていました。まるで修行にお金を払っているようでした。子供や高齢者がいる場合は、さらに悲惨です。どうしても行きたい場合は、もっと寒い時期に行くことをお勧めします。公園はそれほど広くなく、標識も分かりにくく、かなり歩きました。花火の前に諦めて、ホテルに戻って休みました。
・これに対して、9つの個別論点が抽出される。これらが論点(argument)だ。
・オープン初日は行列が制御できず混乱していた
・チケットシステムが頻繁にクラッシュした
・人気アトラクション(ジープ)に乗れなかった
・公園内の行列に日陰がなく、天候の影響を受けやすい
・子供や高齢者には過酷な環境
・寒い時期の来園を推奨
・公園があまり広くなく、標識が分かりにくい
・園内をかなり歩く必要がある
・花火を見る前に疲れてホテルに戻った
・論点は以下の10クラスターに分類された。それぞれをざっと紹介するが、詳細はレポートに掲載されているので、そちらを参考にしてほしい。
【利便性の課題】
1. 待ち時間・混雑による利用体験の不満
アトラクション待ち時間3〜4時間が常態化し、1つしか体験できないケースが多発。これが最大の不満要因となっている。
2. チケット・入場システムの不便さと運営対応
プレミアムチケット依存の構造、アプリの頻繁なクラッシュ、整理券システムの不具合など、IT面での課題が深刻。
【運営・サービス面の課題】
3. 天候・環境への対応と快適性
沖縄特有の高温多湿、台風、雷雨への対策不足。屋根付き休憩所や屋内避難場所の不足が指摘されている。
4. 価格・サービス満足度への不満
案内表示不足、飲食施設のキャパシティ不足、料金設定への不満など、運営・サービス面での総合的な課題。
【体験・コンテンツ面の評価】
5. アトラクション・施設の充実度と体験品質
一部アトラクション(バギー、ダイナソーサファリ等)は高評価だが、運営面の不備が体験を損なっている両極化状態。
6. 恐竜・ジャングルテーマの再現度と体験クオリティ
「恐竜が動かない」「ジャングル感がない」など、メインテーマへの期待と現実のギャップが大きい。
【マーケティング・コミュニケーション】
7. 過剰宣伝と実体のギャップ
CMや公式動画が実際より誇大で、特に遠方からの来場者の落胆が大きい。期待値コントロールの失敗。
8. レストラン・飲食体験と運営対応
一部メニューは高評価だが、レビュー管理への不信感やキャパシティ不足が問題となっている。
【ポジティブ評価】
9. スタッフの接客・ホスピタリティ(唯一の高評価クラスター)
混乱状況下でも丁寧な対応、笑顔の接客が高く評価されている。これが唯一の明確な強み。
10. 再訪意向・今後への期待
現状満足度は低いものの、「今後の改善への期待」という前向きな意見も一定数存在。
・「スタッフの接客・ホスピタリティ」について。全体的にネガティブ意見が目立つ中、「スタッフは頑張っている」というフォローが含まれる投稿が目立つ。「運営は憎いが従業員は保護すべきだ」という風潮がある気がしている。
・なんかこれ、好きじゃないんですよね。大きなものは叩いて良いけど、目に見えるものは叩きたくない=自分の良心を傷つけたくないという身勝手さが滲み出ているようで。組織にネガティブコメントを付けることで結局スタッフは困ることになるけどな。
終わりに
・今回はSerpAPIを使ってGoogleMapのレビューを収集し、TttCを使って加工・可視化を行なった。大規模なデータセットを相手にする場合、1件1件のレビューを閲覧することは現実的ではないし、生成AIに丸ごと投げてもコンテキストウィンドウの上限があり適切な分析はできない。そんな時にTttCは非常に便利だ。ある程度の傾向をまとまって可視化できるので、対策なども立てやすい。
・今回、自分で手を動かして分析することで、幾分かスッキリした気持ちになった。多くのメディアでは、意図的に目立つレビューを取り上げて当該の施設を批判したり、全然施設とは関係のない経営者を槍玉に上げて叩くような姿勢が見られる。自分にとって都合の良いデータを使って印象操作をしているケースが目立つのだ。それを受動的に受けるだけでは、意見は流されてしまいがちだ。
・このように我々の手の届くところにレビューデータは存在するので、それらを俯瞰的に見ることで冷静な判断ができるようになる。感情的な批判や称賛に流されず、データに基づいた建設的な議論こそが、より良いサービスや体験の実現につながるのではないだろうか。
・例えば自身のビジネスでも口コミやアンケートを分析する機会があると思う。そのような際にぜひ使ってみてはいかがだろうか。